

Introduction:
In this blog, we will learn How to process billions of records using Azure Data Factory, Data Lake and Databricks.
Each step mentioned here will be explained in detail in subsequent articles.
Problem Statement:
We are having billions of audit data in Azure table storage and want to generate a high-level report so that the management team can take some important decisions.
We tried different approaches to solve the problem.
Attempt with Approach 1:
Export Azure table storage data into a CSV file and perform a reporting using Excel.
Limitation:
Excel won’t hold more than the 1 million lines of data.
Attempt with Approach 2:
Migrated data to SQL server to process billions of records.
Limitation:
The SQL Server couldn’t handle large data processing and a simple query on it took more than 2.5 – 3 hours to execute.
Attempt with Approach 3:
Directly connect Power BI to Azure table Storage.
Limitation:
Power BI does not support a direct Query on Azure Table Storage. It tried to load a complete dataset on a local machine, which is not feasible in a practical situation.
Finally, we found a solution, how to process billions of data using Azure Data Lake, Data Factory and Databricks.
Below is the high-level diagram depicting the approach to solving this critical business requirement.
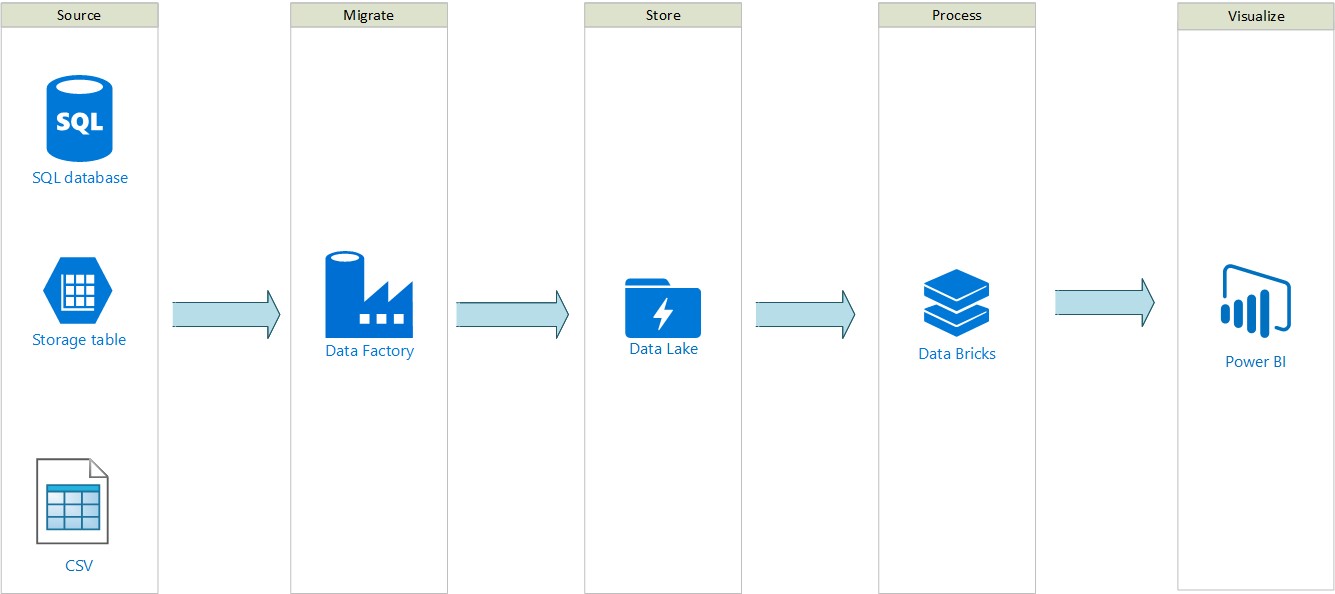
Let’s understand the step by step process of configuring various services and facilitating communication between different resources, to achieve the desired business solution.
Steps:
1. Create a Resource Group.
2. Create an Azure Data Lake account.
3. Create an Azure Data Factory.
4. Transfer the data from Table Storage to Azure Data Lake using Azure Data Factory.
5. Create an Azure AD application for Azure Databricks.
6. Assign a Contributor and Storage Blob Data Contributor role to the registered Azure AD Application at a subscription level.
7. Create an Azure Databricks service.
8. Connect Azure Data Lake to Azure Databricks using Notebook.
9. Connect Power BI to Azure Databricks for better visualization.
This approach will work for other sources as well. Example SQL Database, Cosmos DB, CSV.
In a series of blogs, we will see how each of the above steps can be configured. The next blog will start by explaining how a resource group can be created.